首页
程序员
解决方案
招聘用人
云端工作
自由工作、远程工作
项目研发
需求梳理
规划落地您的想法
整包开发
一站式软件开发
作品
发布需求
开发者入驻
APP
登录
/
注册
技术
全部
Python
Java
PHP
C
C++
Android
iOS
Shell
Go
Rust
Ruby
Kotlin
Swift
Node.js
Unity3D
Object-c
Dart
Solidity
TypeScript
Perl
更多
行业
全部
人工智能
区块链
工业互联网
企业服务
金融
游戏
智能硬件
云计算
电商
开发工具
项目任务
物联网
机器深度学习
教育校园
内容平台
音视频多媒体
政务
机器人
汽车
生活旅游
医疗健康
社交
低代码
物流仓储
能源
脚本插件
网络安全
VR/AR
科学研究
边缘计算
自动驾驶
量子计算
更多
其他
类型
全部
全部
语言框架
开源项目
产品系统
源文件源码
系统
全部
全部
Web
Android应用
iOS应用
小程序轻应用
Windows
MacOS
HarmonyOS应用
Linux
iPadOS
H5
车载应用
电视应用
Web3
算法模型
嵌入式硬件
LaunchBox
Vibe Coding
全部
Falcon prometheus
开发自动驾驶
产品系统
提高安全。改善自动驾驶,提升驾驶技术,超越人身,超越自身!提高安全。改善自动驾驶,提升驾驶技术,超越人身,超越自身!提高安全。改善自动驾驶,提升驾驶技术,超越人身,超越自身!提高安全。改善自动驾驶,提升驾驶技术,超越人身,超越自身!提高安全。改善自动驾驶,提升驾驶技术,超越人身,超越自身!
36
0
Axure
低代码
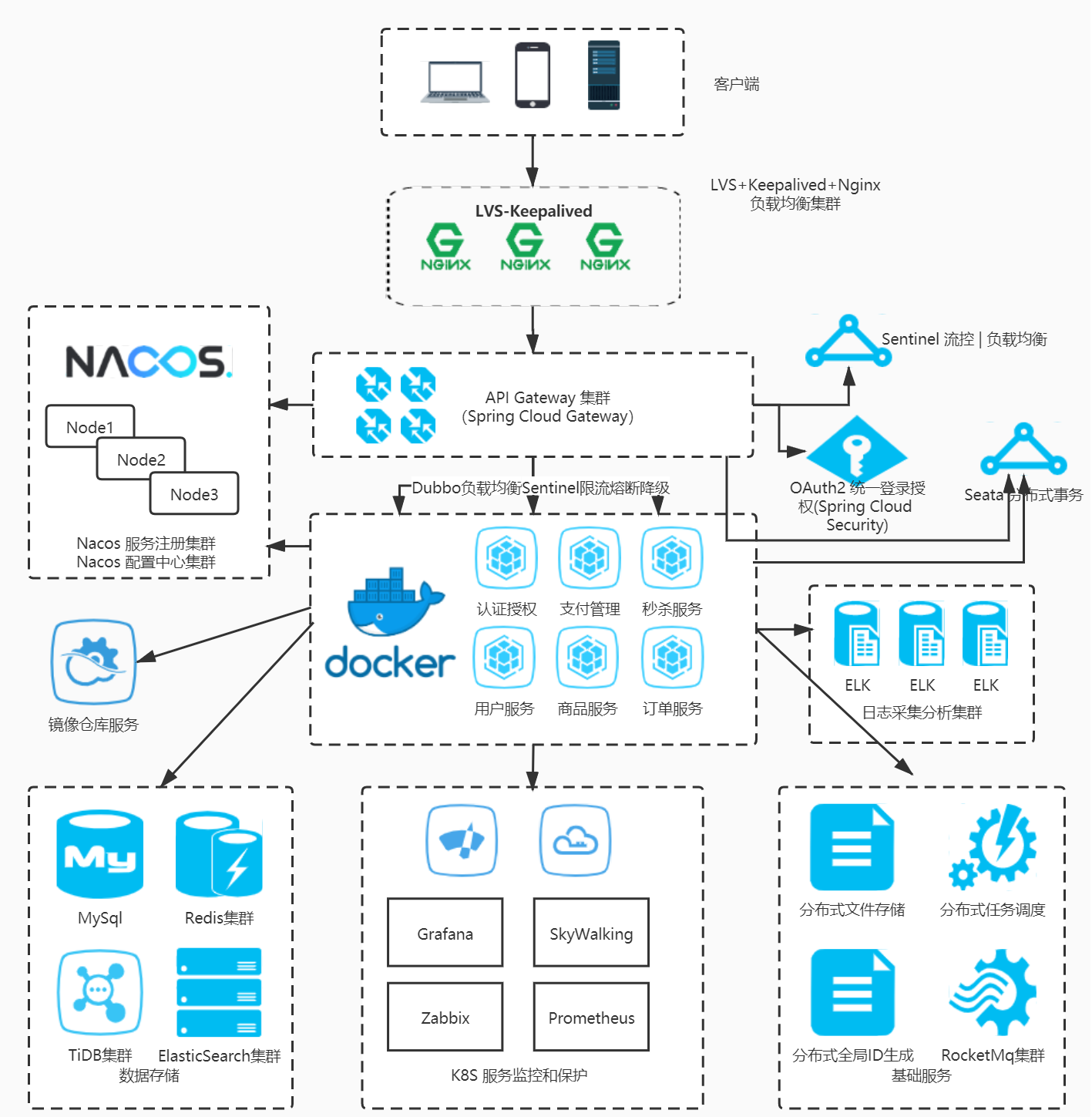
K8S高可用集群从0到1搭建
产品系统
1、APIServer多副本+lb2、etcd集群,存储集群状态,多数节点正常即可读写3、ControllerManager多副本选主,仅leader执行控制循环,备机热备4、Scheduler多副本选主,仅leader执行Pod调度,备机待命5、CoreDNS/CNI多副本+反亲和性,实现服务发现
52
0
K8S
工业互联网
zabbix运维监控项目
产品系统
功能模块:资源资产管理模块、多源监控采集模块、统一告警中心、AI智能故障分析模块、自动化运维执行模块、报表可视化模块。功能描述:平台对接Zabbix、Prometheus两类监控数据源,统一纳管Linux物理机、Windows服务器与K8s容器资源;告警收敛去重后经由AI解析故障根因,联动Herme
68
0
K8S
电商
电商微服务系统
产品系统
go-ecommerce-microservices是一个基于Go的电商微服务系统,核心目标是模拟真实电商后端的商品、订单、购物车等业务链路。项目按微服务拆分为商品写服务、商品读服务和订单服务。商品写服务负责商品创建、修改、删除等写操作;商品读服务负责商品查询、搜索、缓存和读模型维护;订单服务负责订
70
0
RocketMQ
人工智能
技术栈能力等级
产品系统
技术栈能力等级模块,真实呈现开发者核心技术实力。智能评级系统基于项目交付数据、客户反馈与技术认证综合评估,动态更新Python/Go/云原生等技术能力等级,帮助企业快速识别适配人才,提升招聘与合作效率。
62
0
Phalcon
云计算
自研AI项目运维
产品系统
AI大模型自动识别缺陷的物料,人工智能(AI)技术为优化决策提供智能化辅助。该系统利用AI的大数据图像处理能力,将复杂的数据场景转化为清晰、直观的3D可视化展示,让每一个物联网场景方案都能够被快速理解
61
0
K8S
人工智能
CRM微服务迁移项目
产品系统
主导在云上搭建k8s集群及镜像仓库,制定集群维护标准,保障集群稳定运行;负责原有mysql数据迁移至云上,充分利用RDS的PASS特性,搭建数据高可用架构,强化数据安全防护协调开发团队完成域名调试部署、CDN服务新建及业务发布,制定发布流程与回滚方案;新增网络并打通与原有网络的通信,优化网络策略,兼
75
0
K8S
云计算
统一运维平台
产品系统
实现java应用,前端应用,以及各种中间件(mysql、redis、nacos、zookeeper等),以产品化的方式自动部署,并集成Prometheus,grafana,alertmanager,loki等服务,实现监控告警的能力
101
0
Python
企业服务
武汉车城网二期项目
产品系统
1)主导武汉二期项目I层资源规划、业务服务部署网络规划、PAAS层服务部署、业务服务部署。2)项目运维工作:搭建工单系统、知识库系统;日常巡检、输出月度运维报告、输出年度运维报告、用户运维培训等。3)在项目决算审计中主导梳理项目架构、业务数据流;主导审计老师审查的每一个功能交付情况。并配合完成武汉车
267
0
K8S
项目任务
CI/CD 自动化流水线与云原生架构部署项目
产品系统
1. 自动化部署覆盖率达100%,将传统手动部署的2-3小时/次,缩短至15分钟/次,迭代频率从每月2次提升至每周4次,极大提升业务交付效率;2. 云原生集群稳定运行12个月,可用性达99.95%,故障自动恢复时间从小时级缩短至分钟级,减少80%人工运维工作量;3. 通过动态扩缩容与资源优化,集群资
166
0
K8S
金融
将公司业务迁移到K8s集群
产品系统
1. 主导迁移方案设计,结合Linux运维经验制定“评估-容器化-迁移-验证-优化”五阶段实施计划;2. 负责传统应用容器化改造、K8s资源配置与部署,解决迁移过程中系统兼容、依赖适配问题;3. 基于Linux系统基础,搭建K8s集群监控、日志与安全体系,保障迁移后业务稳定性;4. 编写自动化脚本(
206
0
K8S
金融
跨境办公网络优化方案部署(某跨境电商团队)
产品系统
《跨境办公网络优化&云服务器部署服务》(企业跨境团队专用·支持对公)⭐服务简介为做海外业务的中小团队,提供一套稳定、安全、合规的跨境办公访问环境,并协助企业部署香港/海外云服务器,保障团队在国内办公时访问海外工具、后台、服务的稳定性与速度。适合场景: • 跨境电商/独立站团队 • 出海软件/SaaS
242
1
K8S
工业互联网
K8S集群搭建
产品系统
实现离线环境的音视频会议通讯,搭建离线k8s集群,搭建Livekit和AI-agent、ingress异地分布式联邦集群实现AI会议对话,调试sip网关设备,实现电话拨打电话进入会议系统,prometheus监控业务实现,
164
0
K8S
音视频多媒体
移动源排放智能决策支撑系统
产品系统
1.重点移动源监管子系统基于车辆在线监测数据,建立移动源档案与违规分析机制,实现从定位监测到执法线索推送的全流程管控,支撑移动源违规在线处置业务。2.移动源排放分析与决策支持子系统利用流处理与大数据技术,实时分析联网数据,构建道路排放清单与时空特征图谱,实现从微观到宏观的排放分析。开展温室气体专题评
311
0
Python
企业服务
运维体系建设、长线运维
产品系统
监控体系的调研、选型与落地公司自建虚拟化云原生架构的部署与落地国内外公有云实践经验运维系统开发工作,包括cmdb、客服系统、流程平台等python、shell开发工作
164
0
K8S
游戏
云平台运维项目
产品系统
1.作为项目经理主持完成公司中云信站点IAAS平台(4个机架20个计算节点)建设工作,保障了业务系统按时投产;2.负责建设公司的日志管理平台,接入了IAAS平台业务日志和所有网络设备,安全设备的硬件日志,根据业务规则需求对日志进行分析处理,收集存储。配置监控告警策略监控异常业务日志并推送告警通知;3
311
0
Zabbix
金融
海外社交运维日活量50万
产品系统
1.负责公司运维体系构建,包括标准规范制定、持续集成、监控告警、安全防护等方面,整体对运维的质量、效率、成本、安全负责;2.管理运维工作,包括网络/硬件规划管理、IDC机房、系统运维、数据库运维、应用运维、自动化运维等,针对各级业务系统的架构、部署、监控、治理、优化、容灾、安全等进行规划和实施指导3
197
0
K8S
人工智能
Grafana全家桶(Alloy+Loki+Prometheus+Mimir+Grafana)轻量级
产品系统
1.统一数据采集(Alloy)轻量高效:采用Go语言编写的单一二进制文件,资源占用远低于同时部署多个传统Agent。多源兼容:原生支持Prometheus指标采集、Loki日志采集、OpenTelemetry遥测数据等,是面向未来的统一采集器。强大的处理能力:内置灵活的流水线处理机制,可以在数据发送
544
0
K8S
游戏
awesome-yuan
开源项目
提供一套能够实现快速搭建环境的docker-compose集合。此集合精心整合了各类在开发与运维过程中极为常用的数据库集群。通过使用这一集合,用户能够便捷、高效地构建起所需的数据库环境,大幅缩短搭建时间,提升工作效率,助力项目快速推进。无论是用于测试、开发还是生产环境,该docker-compose
150
0
K8S
开发工具
开发机器学习平台
产品系统
从0到1开发机器学习平台 纳管多个云上的gpu和cpu-k8s集群 任务功能 多集群多队列多用户组 gpu多机训练,tensorboard可视化 工作流cpu/gpu数据处理 云仿真,单机仿真任务 开发机 gpu-share开发机1虚n gpu双卡开发机 cpu开发机 save镜像 原地重启 cfs/pfs持久化存储 alluxio缓存 4种维度监控、本地和云平台日志 支持优先级
236
0
Go
AI
当前共31个项目
登录查看更多
登录
登录后即可上传、下载作品
分类
HTTPS
ElasticSearch
服务器测试
Laya
Apache
MySQL
驱动开发
Clojure
Ada
功能测试
×
寻找源码
源码描述
联系方式
提交
重点城市程序员兼职推荐
北京程序员兼职
上海程序员兼职
深圳程序员兼职
广州程序员兼职
杭州程序员兼职
成都程序员兼职
南京程序员兼职
武汉程序员兼职
西安程序员兼职
重庆程序员兼职
郑州程序员兼职
长沙程序员兼职
苏州程序员兼职
合肥程序员兼职
厦门程序员兼职
济南 程序员兼职
青岛程序员兼职
天津程序员兼职
大连程序员兼职
福州程序员兼职
石家庄程序员兼职
沈阳程序员兼职
太原程序员兼职
无锡程序员兼职
南昌程序员兼职
哈尔滨程序员兼职
南宁程序员兼职
珠海程序员兼职
宁波程序员兼职
昆明程序员兼职
东莞程序员兼职
贵阳程序员兼职
美国程序员兼职
长春程序员兼职
温州程序员兼职
佛山程序员兼职
常州程序员兼职
呼和浩特程序员兼职
兰州程序员兼职
乌鲁木齐程序员兼职
中山程序员兼职
海口程序员兼职
洛阳程序员兼职
更多
重点岗位程序员兼职推荐
C++兼职
Rust兼职
小程序兼职
cocos2d-x兼职
Unity3D兼职
DBA兼职
运维兼职
测试兼职
Go兼职
UE设计师兼职
全栈兼职
技术创始人兼职
CTO兼职
架构师兼职
产品经理兼职
Java兼职
PHP兼职
C兼职
C#兼职
Python兼职
Ruby兼职
Node.js兼职
Android兼职
iOS兼职
前端兼职
UI设计师兼职
原画师兼职
项目经理兼职
Vibe Coding兼职
HarmonyOS兼职
区块链兼职
人工智能兼职
硬件开发兼职
移动其他兼职
更多