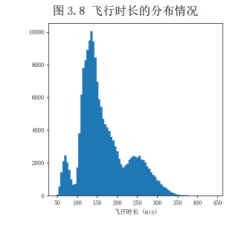
压力平衡项目要解决的问题是某前置仓全局压力的衡量与监控,当前置仓运力与用户需求出现异常不匹配时,及时有效的使用调控手段(订单量限制)来平衡需求与供给。压力系数是门店供需平衡的数值体现.压力系数越大说明门店配送压力越紧张,根据不同的压力情况给出站点最为有效的调控手段来保证用户履约质量与人力的平衡。
技术点:
该项目分为三部分,首先是底层背单量模型,根据历史21天骑手跑动趟次数据构建LR模型,滑动预估骑手每趟不同背单量情况下的背单能力得到预估超时率,每日凌晨计算更新骑手当天的最大背单量数据。其次是压力的计算,确定时间窗口内的未完成订单量,压力系数 = 前置仓未完成订单量/骑手背单能力之和。最后是调控策略,根据压力系数判断当前门店压力高低,继而计算未来时间片内能承载的最大单量,实时更新,实现前置仓智能调控/限单。我这边主要负责的是第一、第二部分。