资产管理系统是一种**以实物管理为核心,利用计算机为操作平台,通过条形码等先进技术实现对固定资产全生命周期的监管和管理的系统**。
具体来说,资产管理系统的主要功能和特点包括:
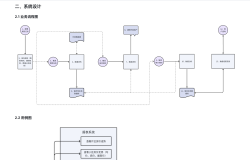
1. **资产跟踪**:系统可以对资产从采购、入库、出库、调拨、借用到报废的全过程进行监控和管理,确保资产使用的透明性和可追溯性。
2. **流程管控**:通过规范的管理流程,系统提高了资产的利用率和管理效率,使得审批中的数据和业务流程能够快速自动化流转。
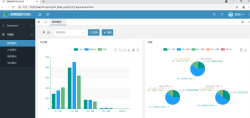
3. **账物相符**:系统能够实现账目与实物的一致性,通过盘点和统计报表等功能确保资产信息的准确性。
4. **折旧计算**:根据固定资产的实际情况和国内惯例,系统可以采用平均年限法等方法对固定资产进行折旧计提。
5. **功能全面**:系统涵盖了资产档案管理、采购管理、使用管理、处置管理、盘点管理和数据查询等多个方面的信息化管理,同时也支持根据用户需求进行定制开发。
6. **结构灵活**:资产管理系统通常采用B/S或C/S结构,结合分布式数据库技术,以适应不同企业的需求。
7. **操作便捷**:系统支持在线发起采购申请、移动审批等操作,提高了工作