






1、行业背景: 电商数据分析与市场研究行业
业务场景:
- 商品价格监控: 帮助商家和消费者监控竞品价格变化,制定合理的定价策略
- 市场调研分析: 为电商从业者、数据分析师提供市场趋势和商品热度数据
- 竞品分析: 支持企业进行竞争对手商品信息收集和分析
- 数据驱动决策: 为电商运营、产品选品、库存管理提供数据支持
目标用户: 电商从业者、数据分析师、市场研究人员、个人用户
2、
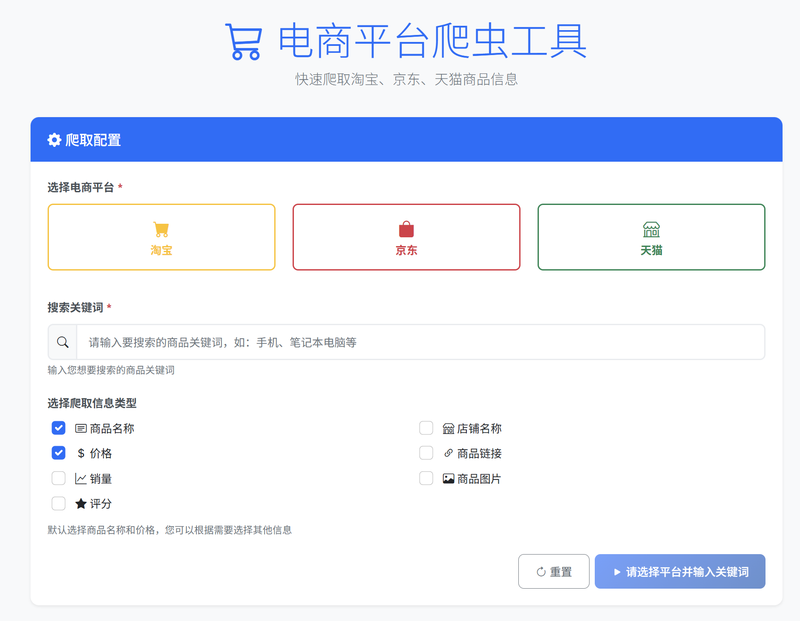
- 多平台支持: 支持淘宝、京东、天猫三大主流电商平台
- 智能爬取: 可配置爬取商品名称、价格、销量、评价等多维度信息
- 反爬虫应对: 内置多种反爬虫策略,包括请求延迟、User-Agent轮换等
数据处理模块
- 数据清洗: 自动去重、格式标准化、异常数据过滤
- 数据存储: 基于SQLAlchemy的数据库存储,支持SQLite
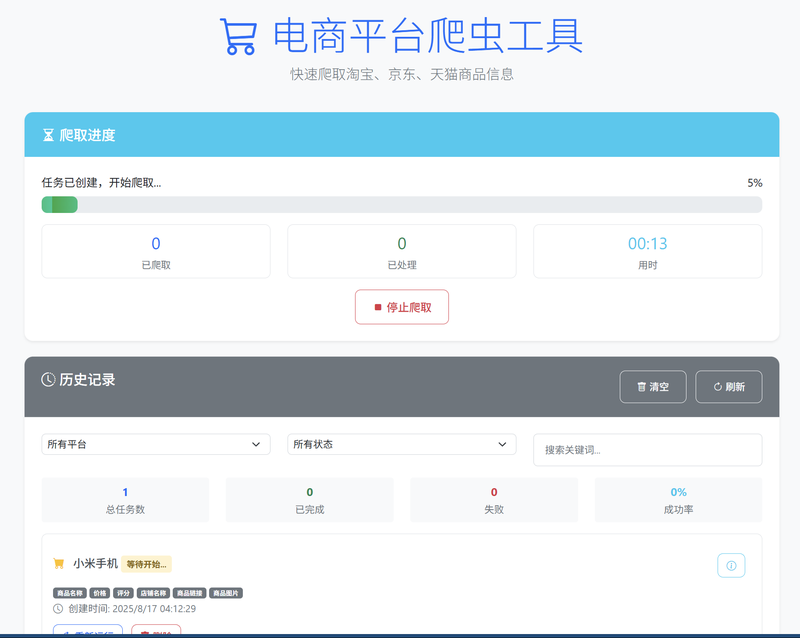
- 历史记录: 完整的爬取任务历史和数据版本管理
导出管理模块
- 多格式导出: 支持CSV、Excel、JSON等多种数据导出格式
- 批量处理: 支持大批量数据的高效导出
- 文件管理: 统一的下载文件管理系统
Web界面模块
- 用户友好界面: 基于Flask的Web应用,提供直观的操作界面
- 任务管理: 可视化的爬取任务创建、监控和管理
- 实时状态: 爬取进度实时显示和状态更新
系统服务模块
- 爬虫控制器: 统一的爬虫任务调度和并发控制
- 数据库服务: 完整的数据CRUD操作和查询服务
- 错误处理: 完善的异常处理和错误恢复机制
3、
后端框架:
- Flask 2.3.3+: 轻量级Web框架,快速开发和部署
- SQLAlchemy 2.0.23+: ORM框架,提供数据库抽象层
爬虫技术:
- Selenium 4.15.2+: 动态网页爬取,支持JavaScript渲染
- BeautifulSoup4 4.12.2+: HTML解析和数据提取
- Requests 2.31.0+: HTTP请求库,处理静态页面
数据处理:
- Pandas 2.1.3+: 数据分析和处理
- NumPy 1.25.2+: 数值计算支持
- OpenPyXL 3.1.2+: Excel文件处理
1. 分层架构设计
- 表现层: Flask路由和模板系统
- 业务层: Services服务层处理核心业务逻辑
- 数据层: Models数据模型和数据库操作
- 爬虫层: 独立的爬虫模块,支持多平台扩展
2. 模块化设计
- 高内聚低耦合: 各模块职责明确,便于维护和扩展
- 插件化爬虫: 基于BaseCrawler的继承体系,易于添加新平台
- 配置驱动: 多环境配置支持(开发、生产、测试)
3. 可扩展性
- 平台扩展: 新增电商平台只需继承BaseCrawler
- 功能扩展: 模块化设计支持功能快速迭代
- 部署灵活: 支持单机部署和分布式扩展
4. 稳定性保障
- 异常处理: 完整的异常体系和错误恢复机制
- 测试覆盖: 基于pytest的完整测试套件
- 日志系统: 分级日志记录,便于问题排查
5. 用户体验
- Web界面: 直观的操作界面,降低使用门槛
- 实时反馈: 任务进度和状态实时更新
- 数据可视: 多种格式的数据导出和展示

点击空白处退出提示
评论