


本项目面向高校图书馆借阅推荐场景,主要解决学生面对大量图书资源时难以快速发现感兴趣书籍的问题。传统图书检索依赖关键词搜索,无法充分利用用户历史借阅行为、图书类别、作者、出版社等信息进行个性化推荐。系统通过分析用户历史借阅记录、图书基础信息和交互行为,构建用户画像与图书特征,结合协同过滤、热门召回和机器学习排序模型,为每位用户生成个性化图书推荐结果。该项目适用于高校图书馆、校园阅读平台、教育资源推荐系统等业务场景。

点击空白处退出提示



本项目面向高校图书馆借阅推荐场景,主要解决学生面对大量图书资源时难以快速发现感兴趣书籍的问题。传统图书检索依赖关键词搜索,无法充分利用用户历史借阅行为、图书类别、作者、出版社等信息进行个性化推荐。系统通过分析用户历史借阅记录、图书基础信息和交互行为,构建用户画像与图书特征,结合协同过滤、热门召回和机器学习排序模型,为每位用户生成个性化图书推荐结果。该项目适用于高校图书馆、校园阅读平台、教育资源推荐系统等业务场景。
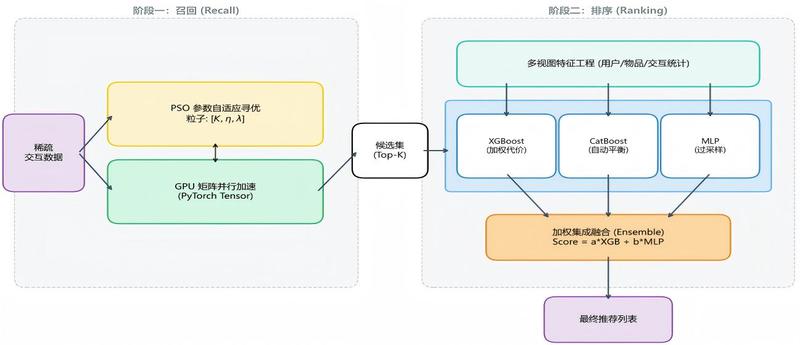
系统主要包含数据预处理、候选图书召回、特征工程、模型训练、推荐排序和结果导出等功能模块。
1. 数据预处理:对用户信息、图书信息、借阅记录进行清洗、去重、缺失值处理和格式统一;
2. 候选召回:基于用户历史借阅行为、相似用户协同过滤、图书热度等策略生成候选图书;
3. 特征工程:构造用户活跃度、图书热度、类别偏好、历史交互、时间统计等特征;
4. 模型排序:使用机器学习模型对候选图书进行排序,输出每个用户最可能感兴趣的图书;
5. 离线评估:支持 Precision、Recall、F1 等指标评估推荐效果;
6. 结果导出:按指定格式生成推荐结果文件,便于提交或系统集成。
本人主要负责项目的数据处理、推荐算法设计、特征工程、模型训练、离线评估和结果生成等工作。
项目使用 Python 作为主要开发语言,基于 pandas 和 NumPy 完成数据清洗与特征构造,使用协同过滤方法进行候选图书召回,并结合 LightGBM / scikit-learn 模型进行排序预测。系统采用“召回 + 排序”的推荐架构:先通过用户行为相似度和图书热度生成候选集,再构造多维特征输入排序模型,最后为每位用户输出 Top-N 推荐结果。
实现难点主要包括稀疏交互数据下的候选召回、用户冷启动问题、特征有效性筛选以及离线评估指标优化。项目最终能够完成从原始数据读取、特征生成、模型训练、推荐预测到结果导出的完整流程,具备较好的可复现性和扩展性。
评论