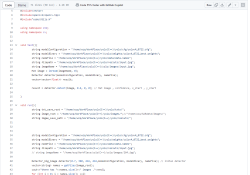
该科研项目提出并且通过实验证实了一种通过向Stable Diffusion模型增加一个基于CNN特征提取网络的人物形象编码器来实现让Stable Diffusion在生成模型未见过的形象时可以不需要额外训练或者微调主模型或者Lora模型。
文中提出了三种技术路线,最终在其中一种技术路线中成功实践并且在较少数据集上得出了有效的结果,证明了技术路线的可行性。
论文摘要:
The current state-of-the-art Diffusion model has demonstrated excellent results in generating images. However, the images are monotonous and are mostly the result of the distribution of images of people in the training set, making it challenging to generate multiple images for a fixed number of individuals. This problem can often only be solved by fine-tuning the training of the model. This means that each individual/animated character image must be trained if it is to be drawn, and the hardware and cost of this training is often beyond the reach of the average user, who accounts for the largest number of people. To solve this problem, the Character Image Feature Encoder model proposed in this paper enables the user to use the process by simply providing a picture of the character to make the image of the character in the generated image match the expectation. In addition, various details can be adjusted during the process using prompts. Unlike traditional Image-to-Image models, the Character Image Feature Encoder extracts only the relevant image features, rather than information about the model's composition or movements. In addition, the Character Image Feature Encoder can be adapted to different models after training. The proposed model can be conveniently incorporated into the Stable Diffusion generation process without modifying the model's ontology or used in combination with Stable Diffusion as a joint model.