背景:
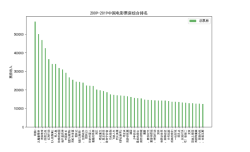
妊娠期糖尿病(GDM)发病率极高,高达20%的孕妇妊娠期间会罹患GDM,控制不佳的GDM不仅会增加流产、早产、妊娠期高血压、巨大儿、肩难产、新生儿低血糖等围产期并发症风险,还会增加产妇产后罹患II型糖尿病和子代远期发生代谢性疾病的风险,妊娠期间严格管理GDM甚至产后定期随访和必要时生活方式的干预是增强妇儿健康的重要措施。目前我国对于糖尿病的管理模式主要是一般产检+专科门诊的形式,但在中国医护人员相对紧缺、医疗资源分配不均的大环境下,该模式下的GDM病情得不到全程、全天的不间断管控,自测末梢血糖及饮食-运动控制的依从性有待提高,相关并发症的改善效果亟需提升,由此所带来的医疗负担沉重,整个GDM管理模式的改良势在必行。
做法:
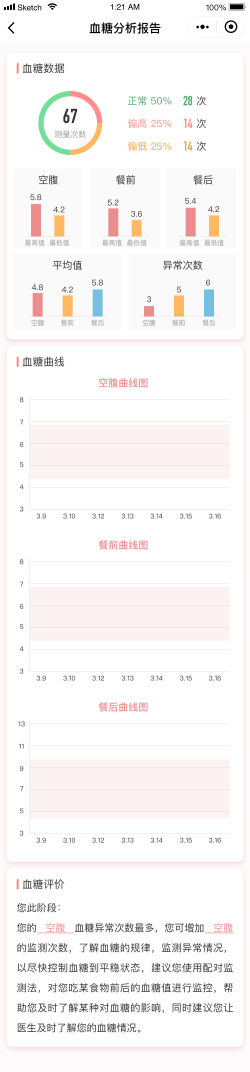
该平台对妊娠期糖尿病患者,基于患者基本信息、血糖数据及其他指标监测数据,辅助医疗人员评估制定患者辅助治疗的饮食、运动、监测管理方案,并基于采集的具体数据信息,对患者进行评估和指导,同时提供切实可行的渐进化干预方案。本产品有助于维持妊娠期糖尿病患者血糖稳定,提升了患者对处方的依从性和完成度,同时能够有效的提升了医疗机构的处方效率,管理效率,有效提供了患者居家血糖数据。