


GenAI 的飞速发展,在创新生成内容的同时也使得图像伪造变得空前便捷与逼真。金融,医疗,社交等关键行业高度依赖用户提交的文本图像(如合同、票据、公告等)进行真实性校验。黑产借助先进的AI生成工具,伪造验真文件,制造不实言论对社会信任、信息安全构成了严峻挑战。由于这些编辑工具的高保真度,传统依赖于低层次的信号特征(JPEG压缩伪影、噪声分布不一致等)方案,缺乏对图像内容的高层语义理解,难以应对无视觉痕迹的伪造攻击。并且这些方案往往黑盒化,可解释性差

点击空白处退出提示



GenAI 的飞速发展,在创新生成内容的同时也使得图像伪造变得空前便捷与逼真。金融,医疗,社交等关键行业高度依赖用户提交的文本图像(如合同、票据、公告等)进行真实性校验。黑产借助先进的AI生成工具,伪造验真文件,制造不实言论对社会信任、信息安全构成了严峻挑战。由于这些编辑工具的高保真度,传统依赖于低层次的信号特征(JPEG压缩伪影、噪声分布不一致等)方案,缺乏对图像内容的高层语义理解,难以应对无视觉痕迹的伪造攻击。并且这些方案往往黑盒化,可解释性差
1、功能模块:
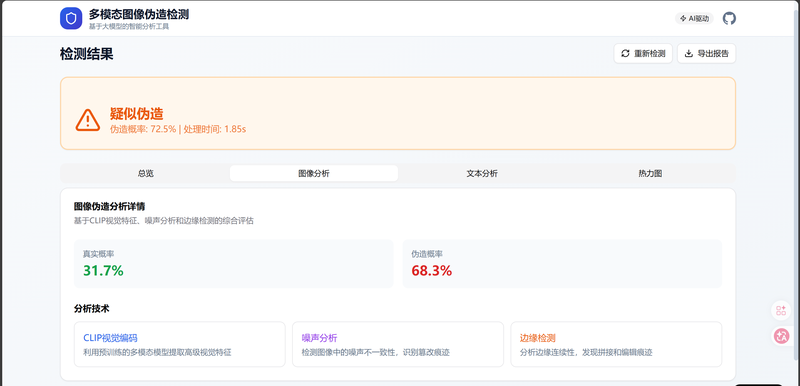
- 图像伪造检测模块:CLIP视觉特征分析、噪声分析网络、边缘检测网络、注意力热力图定位
- 文本伪造分析模块:OCR文本提取、字体一致性检测、语义一致性验证、语法错误检测
- 综合评估模块:多模态特征融合、置信度评估、详细报告生成
- 用户交互模块:拖拽上传、实时预览、结果可视化、报告导出
2、主要功能:
支持单图/批量图像伪造检测,自动提取并分析图像中的文本内容,生成注意力热力图精确定位可疑篡改区域,提供伪造概率评分和置信度判定,输出包含各项指标的专业检测报告,支持报告导出和分享。
1、负责任务:系统架构设计、CLIP视觉特征提取模块实现、噪声分析与边缘检测神经网络构建、多模态特征融合策略设计、Flask后端API开发、React前端界面开发、注意力机制篡改定位、模型训练脚本编写。
2、技术栈:Python + PyTorch + Transformers + Flask + React + TypeScript + Tailwind CSS。架构采用前后端分离设计,后端集成CLIP预训练模型、自定义CNN网络和OCR引擎,前端使用React构建现代化UI。亮点包括多模态特征深度融合、注意力热力图可视化、模块化可扩展架构。难点在于噪声特征鲁棒性提取、注意力定位精度优化、多模态特征对齐。
评论