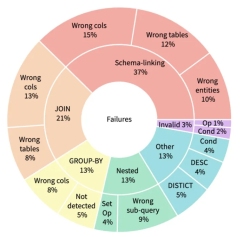
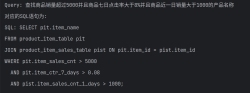
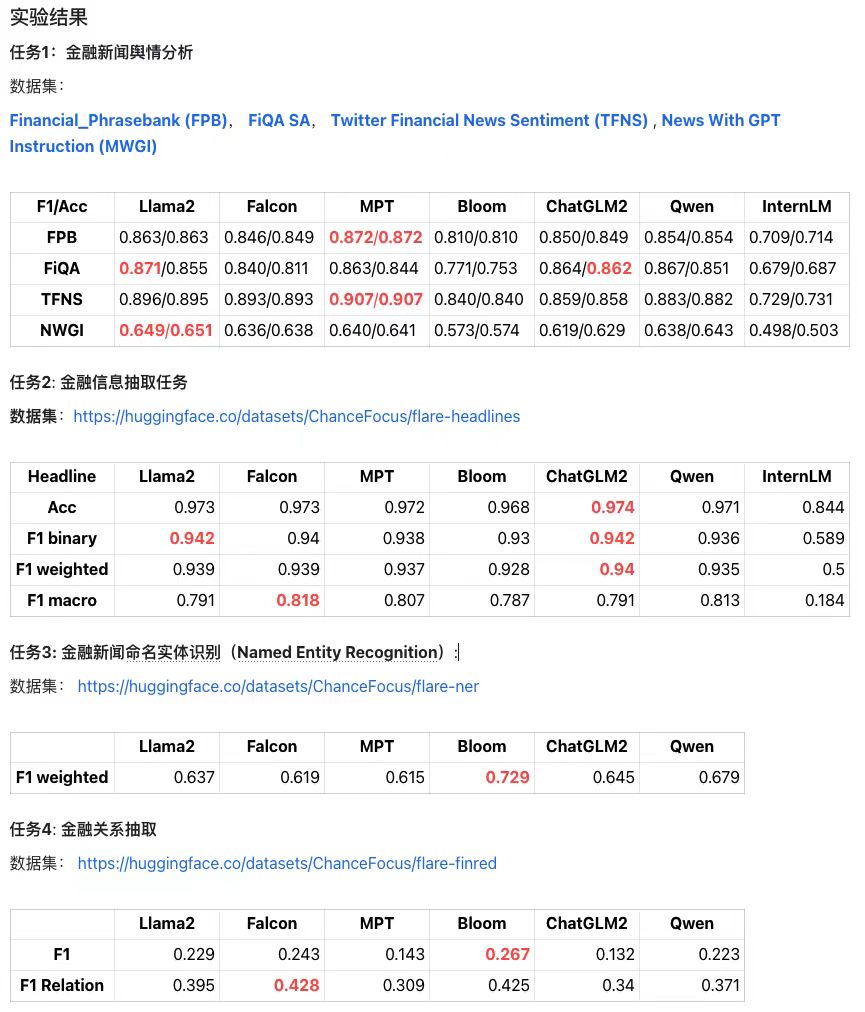
项目简介:
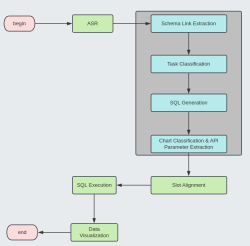
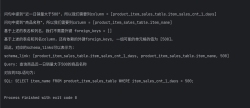
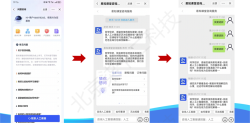
项目的目标是根据用户的输入query,结合大模型配置信息中的多个表的schema信息,返回对应的标准化的SQL语句。
如假设有以下几张表和对应的列:
Table advisor, columns = [*,s_ID,i_ID]
Table classroom, columns = [*,building,room_number,capacity]
Table course, columns = [*,course_id,title,dept_name,credits]
Table department, columns = [*,dept_name,building,budget]
Table instructor, columns = [*,ID,name,dept_name,salary]
Table prereq, columns = [*,course_id,prereq_id]
Table section, columns