


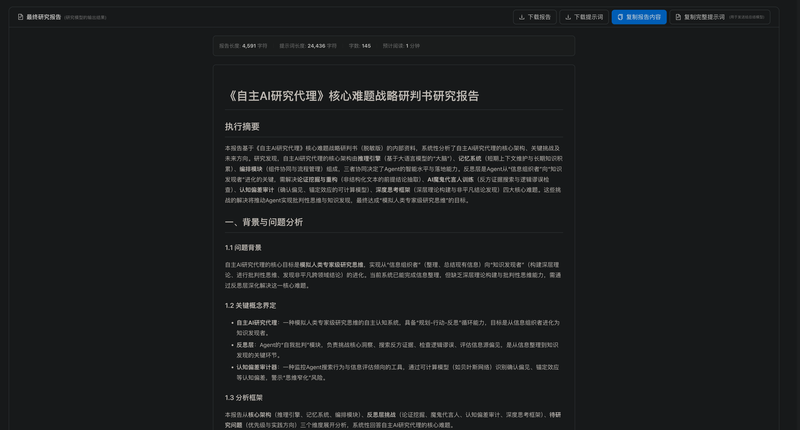
本项目旨在解决知识工作者、研究人员及战略分析师在面对复杂开放性问题时,信息过载与洞察不足的核心矛盾。传统搜索引擎返回的是零散的链接列表,用户需耗费大量时间进行筛选、阅读、整合和分析。Deep Search则通过一个自主AI代理,将这个耗时数小时甚至数天的人工研究过程自动化,从而在商业智能分析、技术趋势研判、学术文献综述等场景下,极大地提升深度信息获取和知识发现的效率与质量。

点击空白处退出提示



本项目旨在解决知识工作者、研究人员及战略分析师在面对复杂开放性问题时,信息过载与洞察不足的核心矛盾。传统搜索引擎返回的是零散的链接列表,用户需耗费大量时间进行筛选、阅读、整合和分析。Deep Search则通过一个自主AI代理,将这个耗时数小时甚至数天的人工研究过程自动化,从而在商业智能分析、技术趋势研判、学术文献综述等场景下,极大地提升深度信息获取和知识发现的效率与质量。
Deep Search 是一个功能完善的自主AI研究平台,其核心功能模块包括:
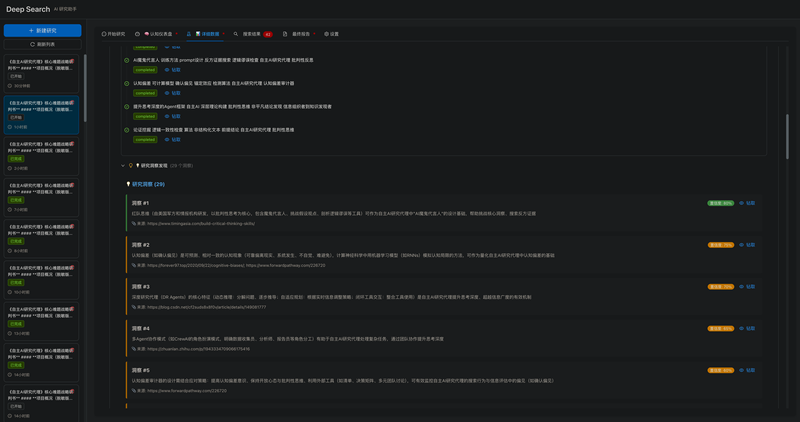
动态研究规划引擎: AI可根据用户问题,结合历史研究上下文,自主地、多轮地生成并迭代研究计划与搜索策略。
异构数据源接入层: 系统通过插件化的元搜索引擎,可同时并行调用通用搜索(如Tavily)、学术搜索(如Google Scholar, Arxiv)等多种数据源,实现信息广度的最大化覆盖。
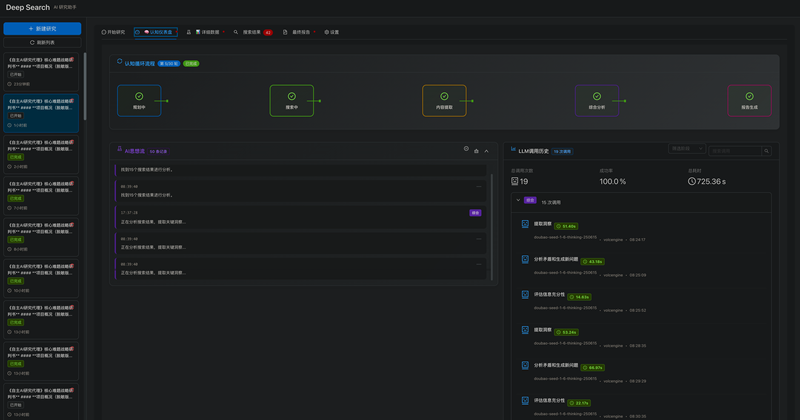
全息认知透视仪表盘: 业界领先的实时监控界面,通过“认知流图”和“实时思想流”将AI的内部思考过程(规划、搜索、综合)与数据流完全可视化,消除黑盒。
双向交互式钻取系统: 所有研究产物(任务、搜索结果、洞察)均建立了可追溯的“血缘关系”。用户可在UI上自由地从任务追溯到结果,或从洞察回溯到原始证据,甚至可以钻取查看每一次LLM调用的完整Prompt和Response。
健壮的流程控制与持久化: 支持长时间研究任务的暂停、恢复与终止,并具备完整的会话持久化和恢复功能。
在该项目中,我主要负责整体的系统架构设计、前端页面设计与构建与核心后端算法的实现。
项目采用了前后端分离的现代化架构,后端基于Python的FastAPI构建,提供RESTful API和WebSocket服务;前端则使用React和TypeScript构建了一个独立的单页应用(SPA)。
评论