



本项目面向棋类与博弈类问题中的智能决策场景,解决传统规则引擎泛化能力弱、人工特征依赖强的问题。通过 AlphaZero 框架,将策略学习与价值评估统一到端到端神经网络中,实现无需人工先验规则的自我博弈训练。适用于棋类 AI 研究、强化学习算法教学、搜索与决策算法验证等场景

点击空白处退出提示



本项目面向棋类与博弈类问题中的智能决策场景,解决传统规则引擎泛化能力弱、人工特征依赖强的问题。通过 AlphaZero 框架,将策略学习与价值评估统一到端到端神经网络中,实现无需人工先验规则的自我博弈训练。适用于棋类 AI 研究、强化学习算法教学、搜索与决策算法验证等场景
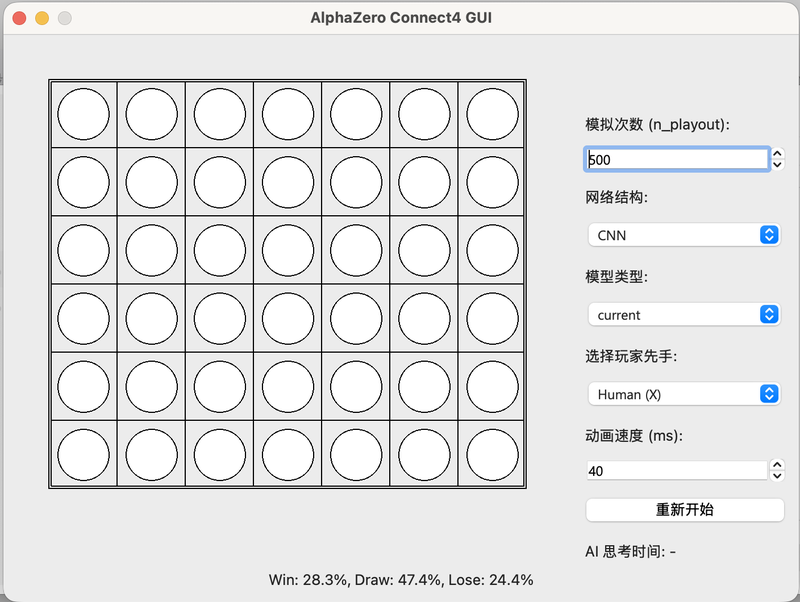
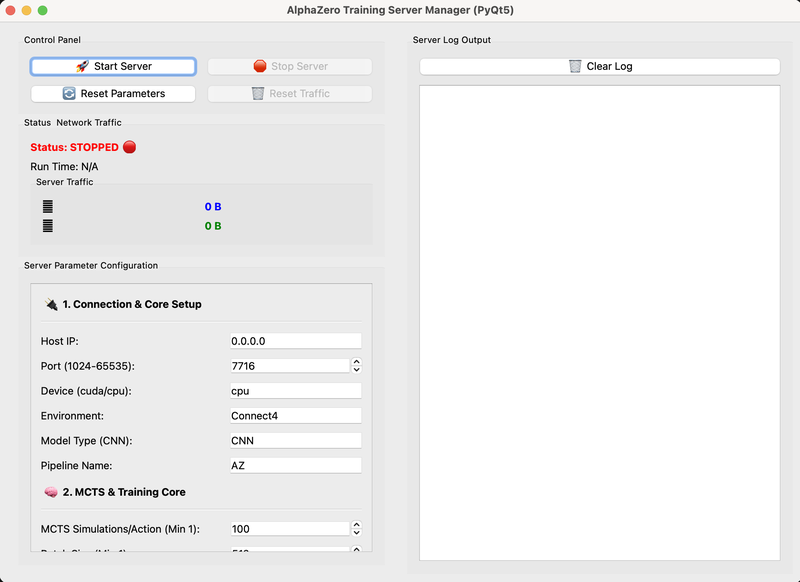
项目实现了完整的 AlphaZero 训练与推理流程,包括自我博弈数据生成、基于 MCTS 的策略改进、策略-价值联合网络训练以及模型评估对弈。支持多种棋类环境扩展(如井字棋、Connect4),结构清晰,模块解耦,便于替换网络结构或搜索策略,用于强化学习与博弈算法的研究与实验。
本人独立完成项目整体设计与核心实现,包括自博弈流程、MCTS 搜索逻辑、神经网络训练管线及实验评估。项目基于 PyTorch 实现策略-价值网络,采用模块化架构,支持算法变体与不同环境接入。在实现过程中重点解决了搜索效率、训练稳定性与算法可扩展性问题,具备较强的科研与工程实践价值。

评论